Friday afternoon discussions can be dangerous. Last Friday I talked with Heinz Pampel from the Helmholtz Open Access Initiative via email about the upcoming BibCamp Hannover (a barcamp for librarians and others interested in online science that will take place this weekend). I said that I was looking for a solution to make the list of publications from our institution more accessible – we currently store them in a regularly updated RefWorks database. Heinz not only told me that there is actually a name for this kind of tool (Current Research Information System or CIRS), but also gave me some good links. This talk by Simon Porter from the University of Melbourne is for example a very good introduction to the topic.
Heinz also suggested BibApp, a nice web-based tool for exactly this purpose written in the Ruby on Rails programming language. Because I am a very familiar with Ruby on Rails, I took a closer look.
Bibapp – Find Campus Experts from Eric Larson on Vimeo.
In the end I spent a good deal of this weekend setting up BibApp, importing all publications from our institution since 2008 via Refworks, starting to add researchers and research groups and adjusting BibApp to our needs (mainly changing the layout to our institution style and starting to translate the templates into German). BibApp is already a fully working system and is telling me some interesting things. This includes many interesting papers from our institution that I didn't know about, but also that two researchers each have published more than 150 papers in two years, and that my colleagues have published 6 papers in Medical Hypotheses since 2008. The technical aspects of setting up BibApp are almost solved (it helps that I run two other Ruby on Rails applications at my institution), so now I have to convince our library and administration that it's worth having (and maintaining) such a CRIS tool.
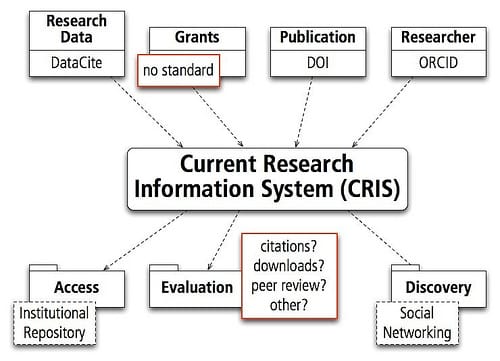
Two weeks ago I wrote about the upper part of the figure (for a NSF workshop that got postponed to September because of the Volcano ash). As far as I can see, there is no standard between funding agencies for grant reporting, and both DataCite and ORCID are fairly new initiatives.
The CRIS can be used to facilitate access to institutional repositories or primary research datasets. BibApp supports the SWORD protocol for article deposition, and it automatically checks all papers against the ROMEO database of publisher copyright policies. A CRIS is a great discovery tool and it can be further enhanced by integration with social networking tools (e.g. with the new Nature Network or the Mendeley API both announced a few days ago).
The main interest of administrations if of course evaluation of research output. A CRIS can be used to do exactly that, and it has two advantages: a) it can automate some of the processes that are currently done manually by researchers (regularly collecting and reporting information about grants and publications), and b) it is a great platform to develop new tools for the evaluation of scientific output. My institution currently evaluates using the Impact Factor of the published papers, and takes first and last authorship (and female authors) into consideration. A CRIS would allow an institution to use similar tools as the PLoS Article-Level Metrics (usage data, citation data, usage by social networking tools) instead of the Impact Factor, and several projects are already trying some of that, e.g. the German Open Access Statistics project.
But the best thing about CRIS tools in general, and BibApp in particular, is that they add a lot of value for relatively little effort. Universities don't want to (and can't) compete with large institutions or companies such as scientific publishers. Because they basically just integrate the data that are already available in an intelligent way (Mashup in Web 2.0 language), they require a reasonable effort to maintain. This will be particularly true once the ORCID system of unique author identifiers is in place, because author disambiguation is currently one of the most time-consuming aspects (even though BibApp is pretty smart about this). I'm looking forward to adapt BibApp to the ORCID prototype system that is planned for this summer.
