Two weeks ago Euan Adie from altmetric.com and myself launched the website CrowdoMeter, a crowdsourcing project that tries to classify tweets about scholarly articles using the Citation Typing Ontology (CiTO). Despite the holidays we have gotten off to a good start with currently 597 classifications by 56 different users, already covering 93% of the tweets we wanted to classify. We will discuss the results of this project at the ScienceOnline2012 conference in two weeks, but the most important findings can also be watched in real-time here.
To our knowledge this is the first time that CiTO has been used for the systematic classification of tweets, and the preliminary results seem to confirm what we and others had thought, i.e. that most tweets contain little semantic information and often only retweet the title of a paper. But not only do we now have numbers to confirm this, but we can also make some interesting additional observations. We find for example that only 1% of tweets disagree with the statements made in a paper – most Twitter users don’t seem to care telling others about papers they dislike or disagree with.
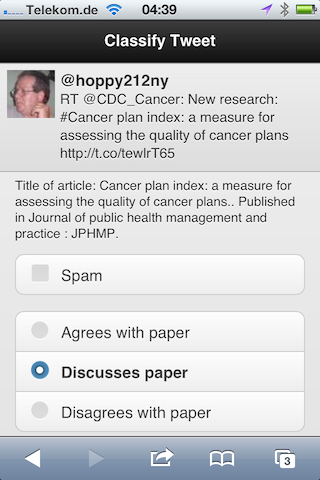
This project is far from over, ideally we want 3-5 classifications per tweet or an additional 1,000 classifications. It is a challenge to build a website so that enough people want to help with this project. One idea is to make the classifications as simple as possible, and to help further with this we today launched a mobile version of CrowdoMeter. Simply browse to http://crowdometer.org with your iPhone or Android phone, sign in via your Twitter account, and you should see something similar to this:

CrowdoMeter uses jQuery Mobile, a touch-optimized Javascript framework for smartphones and tablets. There are still some minor issues, but in general jQuery Mobile is a great tool to optimize a website for mobile users. Users are presented with 10 random tweets they haven’t classified yet, and see a simple classification screen when clicking (touching) a tweet:

It should not take longer than 15 minutes to classify 15-25 tweets, and this would be a tremendous help for the project.
The CrowdoMeter results page displayed the same information as in the desktop version of the website, the charts are produced by the Highcharts Javascript library (and again jQuery).

I’m interested to see how well the crowdsourcing for CrowdoMeter will work in the coming weeks. We hope to finish the data gathering part in January. If this project generates enough interest I could imagine doing another crowdsourcing project, maybe again using the Citation Typing Ontology, but this time for blog posts about scholarly papers.
