Persistent identifiers (PIDs) are not only important to uniquely identify a publication, dataset, or person, but the metadata for these persistent identifiers can provide unambiguous linking between persistent identifiers of the same type, e.g. journal articles citing other journal articles, or of different types, e.g. linking a researcher and the datasets they produced.
Work is needed to connect existing persistent identifiers to each other in standardized ways, e.g. to the outputs associated with a particular researcher, repository, institution or funder, for discovery and impact assessment. Some of the more complex but still important use cases can’t be addressed by simply collecting and aggregating links between two persistent identifiers, including
- Aggregate the citations for all versions of a dataset or software source code
- Aggregate the citations for all datasets hosted in a particular repository, funded by a particular funder, or created by a particular researcher
- Aggregate all citations for a research object: a publication, the data underlying the findings in the paper, and the software, samples, and reagents used to create those datasets.
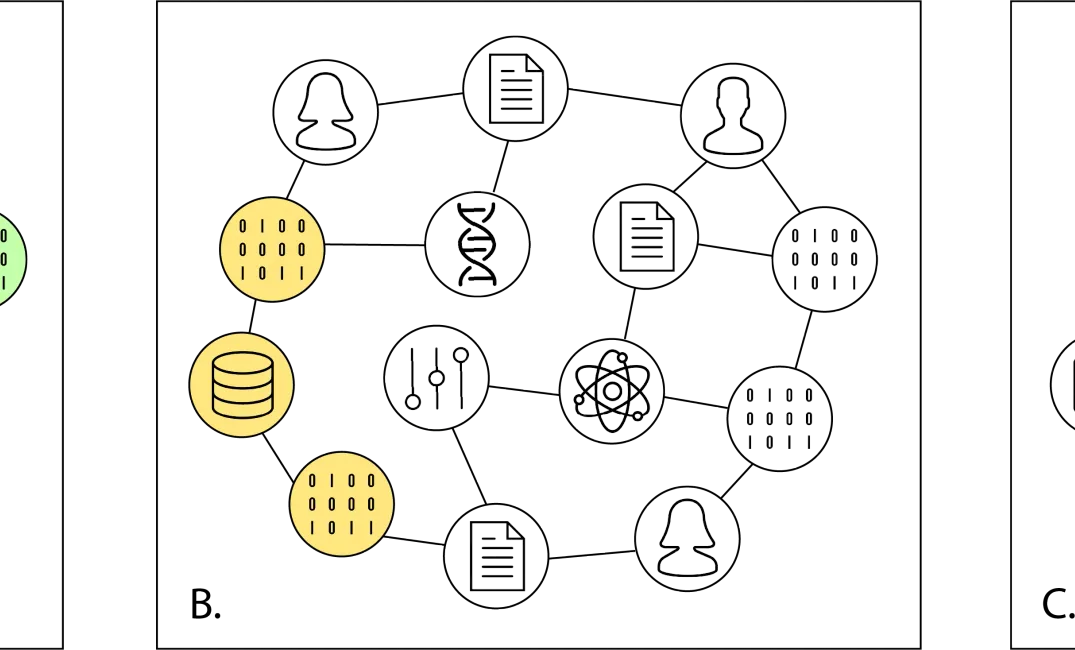
To address these use cases we need a more complex model to describe the resources that are identified by PIDs, and the connections between them: a graph. In graph theory, the resources identified by PIDs correspond to the nodes in this graph, and the connections between PIDs correspond to the edges.
Using a graph makes it easier to describe these more complex use cases and relationships, and this approach has been frequently applied to similar questions in the past. FREYA builds on the expertise and close collaboration with the Research Graph team and adopts the outputs of the Research Data Alliance DDRI Working group to transform PID connections into an improved graph of research objects. This project takes advantage of the best practices of graph modelling and distributed network analysis techniques. We call this the PID Graph.
PID Graph Use Cases
Before starting work on implementing the PID Graph, the FREYA partners collected user stories from their communities relevant to the PID Graph work. We used GitHub issues in a public repository for this activity and then met in person in August 2018 to clarify, group and prioritize these user stories. In total, we identified 48 user stories, described here. The main outcomes of the August 2018 workshop were:
- There is a significant number of relevant user stories that can only be addressed by implementing a PID Graph.
- While there is a diverse number of stakeholder groups and persistent identifier types in these user stories, a number of common themes and major use cases emerged in the workshop.
- We didn’t identify any uses cases that require more than two connections between PIDs, simplifying the required implementation work needed.
After identifying and describing the most relevant use cases, summarized above, we started the implementation work for the FREYA PID Graph. Our goal was to implement the PID Graph as standard production service rather than a research activity or pilot service, so scalability and maintainability are of utmost importance. We learned a lot from the extensive experience gained in the Research Graph initiative and decided to build PID Graph using a set of federated RESTful JSON APIs. PID Graph will not be a single service but federated between FREYA PID providers, FREYA disciplinary partners, and organizations outside of FREYA. PID Graph will be provided by RESTful JSON APIs that describe the resources (nodes) and connections (edges) in this graph. All FREYA PID providers use RESTful JSON APIs to provide PID metadata so that this approach aligns with the extensive existing infrastructure.
Initial PID Graph Implementation
The first working PID Graph implementation is provided by DataCite, extending the existing Event Data Service (Dasler & Cousijn, 2018), a collaboration between Crossref and DataCite. Event Data is a service that provides connections (here called events) between PIDs and other resources, with an initial focus on social media mentions and data citations. The initial PID Graph work done by DataCite since the August 2018 workshop has added these functionalities to DataCite Event Data:
Include metadata about resources
Include not only metadata about connections but also metadata about the resources identified by PIDs. This dramatically simplifies the API calls needed to construct a PID Graph. We do this by optionally including the metadata for the subj and obj (the resources linked via the event) in Event Data via an extra query parameter: https://api.datacite.org/events?include=subj,obj
Including the metadata for subj and obj also enables queries based on resource metadata, e.g. query by type of content that is connected: https://api.datacite.org/events?include=subj,obj&citationType=ScholarlyArticle-SoftwareSourceCode
This query today returns 1,078 events connecting scholarly articles and software, including 834 from journal articles referencing software via Crossref metadata and 210 from software referencing journal articles via DataCite metadata.
Include implicit relations in metadata about resources
Metadata for resources contain a lot of information about connected PIDs. We can take advantage of this by including the information in DataCite Event Data, allowing queries that in effect connect two PIDs via an intermediary resource and two connections. Specifically, we include these relations and associated PIDs:
- Version, e.g. dataset A isVersionOf dataset B (using DataCite relatedIdentifier metadata)
- Granularity, e.g. dataset A isPartOf dataset B or dataset A isSupplementTo article B (using DataCite relatedIdentifier metadata)
- Funding, e.g. dataset A isFundedBy funder B (using DataCite fundingReferences metadata)
- Author, e.g. dataset A isAuthoredBy author B (using DataCite nameIdentifier metadata)
These connected PIDs can then act as a proxy in PID Graph queries, as demonstrated in this example:
https://api.datacite.org/events?include=subj,obj&doi=10.5061/dryad.k5k9074
The query today returns one data citation of the dataset identified by the DOI, and eight data files that are part of this dataset. If someone decides to cite one of these data files instead of the dataset (following principle 8 Specificity and Verifiability of the Joint Declaration of Data Citation Principles (Data Citation Synthesis Group, 2014)), that data citation would also be included in the DataCite Event Data response.
Similarly, the citation of a specific version of a dataset would be included if querying for the parent version of the dataset. Examples for funding and authorship are given in the next paragraph.
Include more types of events
The initial focus in Event Data was on social media mentions and data citations. DataCite has added author-resource links and funder-resource links, using ORCID and Crossref Funder ID as PIDs, respectively. DataCite also include dataset usage statistics, as part of the work in the Make Data Count (Lowenberg, Budden, & Cruse, 2018) project. This enables the following two use cases:
- Show all datasets created by a particular researcher and their usage stats https://api.datacite.org/events?include=subj,obj&orcid=0000-0002-1194-1055. The query today returns four datasets created by a researcher identified via her ORCID ID, plus a combined 21 unique views of these datasets in February and March 2019.
- Show all datasets funded by the European Commission that have been cited by a journal article https://api.datacite.org/events?include=subj,obj&doi=10.13039/501100000780&citation-type=Dataset-ScholarlyArticle. The query today returns 69 datasets cited by 37 journal articles.
Collaborating on Research Data Graph Initiatives
The aim is for any interested parties within and beyond FREYA to implement PID Graph services, meaning that we have to figure out how best to coordinate and enable this federated PID Graph. And of course, there are initiatives outside of FREYA taking similar approaches and addressing similar use cases. These include:
- The already mentioned Research Graph Foundation
- Scholix: a framework for Scholarly Link Exchange coordinated by a Research Data Alliance (RDA) Working Group
- The OpenAIRE Research Graph (Manghi & Bardi, 2019), an open metadata research graph of interlinked scientific products, with access rights information, linked to funding information and research communities.
- Asclepias (Ioannidis & Gonzalez Lopez, 2019), a broker service initially developed to track software citations in astronomy.
To coordinate these activities we have organized a Birds of a Feather session at the RDA Plenary in Philadelphia next week (Wednesday at 2:30 PM): Research Data Graph.
The initial implementation of the PID Graph in DataCite Event Data contains 5.38 million events as of today and more work is needed to convert existing events to the new format (we expect a total of 25 million events with the current data source), improve documentation, and build visualizations and other frontend services to make it easier to show the PID Graph information we already have. But if you can’t wait and are not afraid working with JSON REST APIs, feel free to explore DataCite Event Data, which is a free service with no registration required, by starting with the documentation.
And please reach out to us via the PID Forum if you are interested to learn more about PID Graph, want to see your data in PID Graph, or are working on a related project and want to coordinate. And of course, join us for the RDA Plenary session next week in Philadelphia if you plan to attend the conference.
Acknowledgments
This post has been cross-posted from the FREYA and DataCite blogs. This work was funded by the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 777523.
References
Dasler R, Cousijn H. Are your data being used? Event Data has the answer! In: DataCite; 2018. doi:10.5438/S6D3-K860
Data Citation Synthesis Group. Joint Declaration of Data Citation Principles. Force11; 2014. doi:10.25490/A97F-EGYK
Ioannidis A, Gonzalez Lopez JB. Asclepias: Flower Power for Software Citation. Published online January 24, 2019. doi:10.5281/ZENODO.2548643
Lowenberg D, Budden A, Cruse P. It’s Time to Make Your Data Count! Published online June 5, 2018. doi:10.5438/PRE3-2F25
Manghi P, Bardi A. The OpenAIRE Research Graph - Opportunities and challenges for science. Published online March 20, 2019. doi:10.5281/ZENODO.2600275
