Metadata are essential for finding, accessing, and reusing scholarly content, i.e. to increase the FAIRness [Wilkinson et al. (2016)] of datasets and other scholarly resources. A rich and standardized metadata schema that is widely used is the first step, encouraging users to register these metadata (as many of these are optional and not required) is the second step, while infrastructure providers such as DataCite facilitating metadata registration and making the most of the available metadata is the third step. While we all have put considerable energy into the first two steps, I want to use this blog post to describe what DataCite is doing to improve metadata FAIRness via our services. I will focus on three important optional metadata properties and on two approaches: encouraging metadata registration in a standardized way using the new DOI form in our Fabrica service, and improving discovery via search filters in the next major release of DataCite Search, that we have started development work on.
Language
DataCite metadata can include the primary language of the resource, using either the BCP 47 (e.g. en-US) or ISO 639-1 (e.g. en) controlled vocabularies. In the context of discovery, the ISO 639-1 code is most helpful, as we want to find resources we can understand because we speak the language, and not necessarily care about the nuances of for example U.S. English vs. British English. In Fabrica, the DOI form uses the list of languages in ISO 639-1, and that is also what we will use for filters in search.


Going forward, it would make sense to consider allowing multiple languages per resource. This will not only allow using both BCP 47 and ISO 639-1, addressing different use cases, but will also allow the proper description of multilingual resources.
Rights
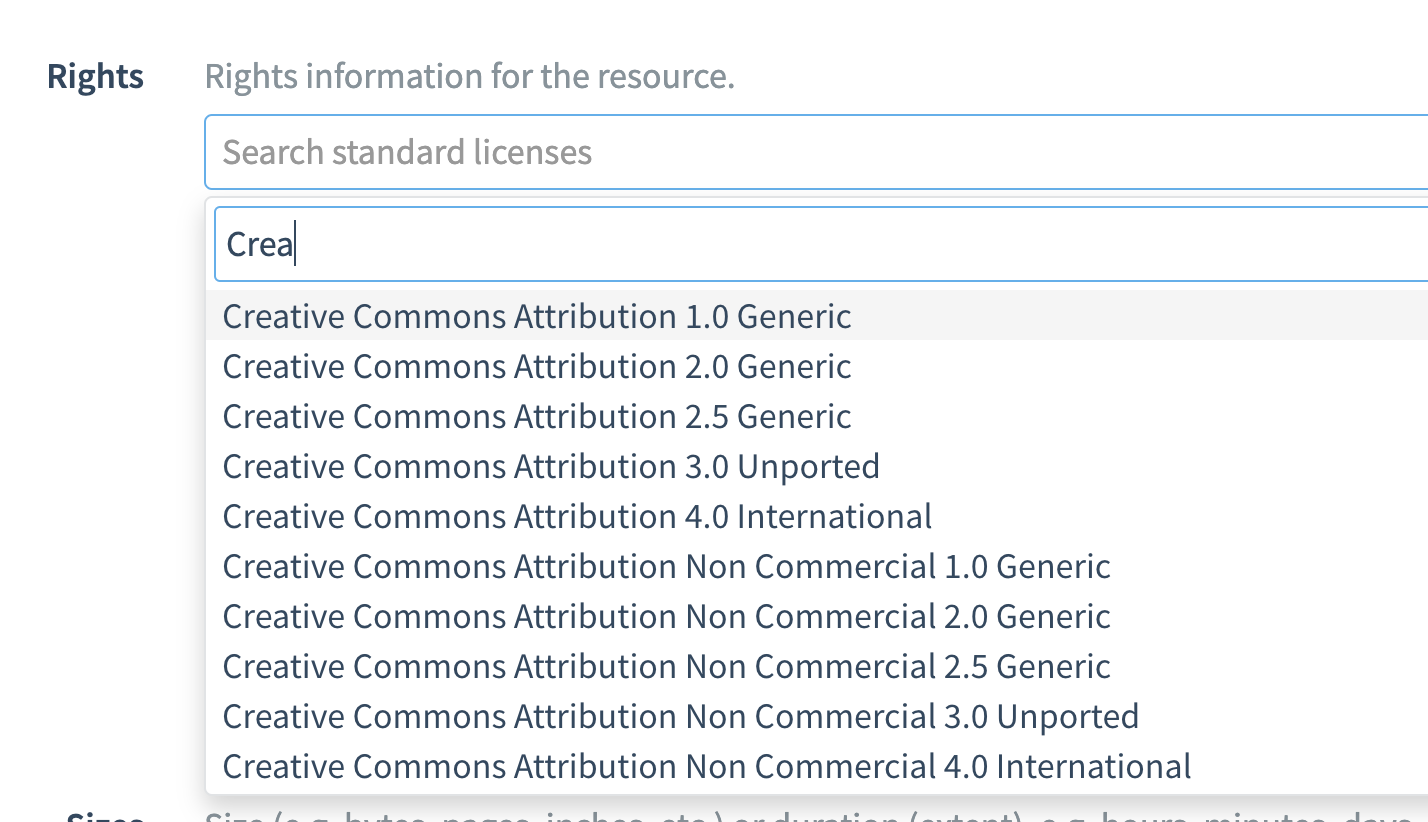
Rights information about a resource is essential, as it informs the user if and under what conditions the resource can be reused. In order to allow users to filter by a specific license, rights information needs to be normalized. In theory, a URL pointing to a specific license is all that is needed, but we also need a human-readable string, and ideally also an abbreviation for the license (e.g. Creative Commons Attribution 4.0 International and CC-BY-4.0 for https://creativecommons.org/licenses/by/4.0/legalcode), and, more importantly, many licenses have more than one URL, e.g.
- http://creativecommons.org/licenses/by/4.0
- http://creativecommons.org/licenses/by/4.0/
- https://creativecommons.org/licenses/by/4.0/
- https://creativecommons.org/licenses/by/4.0/legalcode
We can address this by normalizing the URLs for all licenses, and providing a standard name and abbreviation. Luckily, this work has already been done by the [Software Package Data Exchange](https://spdx.dev/) (SPDX) project of the Linux Foundation. While SPDX focusses on software licenses, it also includes all Creative Commons licenses, which are the most common licenses used in DataCite metadata for data and text. In metadata schema 4.2, released in March 2019, we added the properties rightsIdentifier, rightsIdentifierScheme and schemeURI, and this enables the use of SPDX. In the past few months we have added SPDX support to the DOI form, and we will have search facets based on SPDX.


Subject Area
DataCite metadata have a very flexible Subject property, with sub-properties SubjectScheme, SchemeURI, and ValueURI. Unfortunately there is no standard way to describe the subject area covered by the resource. This makes it difficult to find content described by DataCite metadata in for example Mathematics, or to understand to what extend the various disciplines use DataCite DOIs. There are many subject area classification schemes, but the most widely used generic classification scheme is the OECD Fields of Science classification with 6 top-level categories and 42 subcategories. We have implemented the OECD Fields of Science classification in the DOI form, and will do so in search facets.


While OECD Fields of Science is the most commonly used generic subject classification, the most widely used subject classification we currently find in DataCite metadata is the Australian and New Zealand Standard Research Classification (ANZSRC) Fields of Research. This classification is much more detailed, supporting different use cases. Luckily there is an official ANZSRC mapping to the OECD Fields of Science. This allows us to automatically add the OECD Fields of Science category or subcategory if the ANZSRC Fields of Research is used in DataCite metadata.
Going Forward
We hope that the DOI form makes it easier to register more of the optional but important metadata in a standardized way, and that the new search filters we are launching in a few months will improve discoverability of the content. And that in turn this encourages DataCite members and their repositories to include this information in DOI metadata also when using one of the DataCite APIs for DOI registration. There are sometimes good reason to do things differently, and this also includes metadata for language, rights and subject. The DataCite metadata schema provides the flexibility needed, but we hope that in most cases the standard vocabularies ISO 639-1, SPDX and OECD Fields of Science will be used, improving the finding, accessing, and reusing of scholarly content with DataCite metadata for everyone.
Of course, we shouldn’t forget the important work of the DataCite Metadata Working Group, which is busy working on the next DataCite schema version. That is a topic for another blog post, but I can already tell you that DataCite metadata will better support text documents.
This blog post was originally published on the DataCite Blog.
References
Wilkinson, M. D., Dumontier, M., Aalbersberg, I. J., Appleton, G., Axton, M., Baak, A., … Mons, B. (2016). The FAIR guiding principles for scientific data management and stewardship. Scientific Data, 3(1). https://doi.org/10.1038/sdata.2016.18
