Today DataCite received an email from a user alerting us that there are some small inconsistencies with our recommended data citation format:
Creator (PublicationYear): Title. Publisher. Identifierat https://www.datacite.org/services/cite-your-data.html
Creator; (PublicationYear): Title; Publisher. IdentifierRemoving two semicolons at data.datacite.org looks like an easy fix, but this is a bit more complicated since the data citation at data.datacite.org is automatically generated using an existing citation style, which looks just slightly different (http://citationstyles.org/ doesn't have a DataCite style). Support for data citation style is a topic for another blog post, but here I want to talk about what it takes to make changes to DataCite's website or services to fix a bug or add a feature.
In most cases even small changes like this one require us to deploy new code. Fixing the code in place is usually a bad idea because it makes it hard to track changes over time. When we deploy new code we have to make sure that we are really only making that small change and not changing something else in the process, e.g. because a support library is automatically updated to a newer version. So we should run tests to make sure everything is ok and we have to deploy the new code to our test system first. Before we know it this seemingly small change becomes a bigger undertaking.
The end result is of course - and this is not something limited to DataCite - that we deploy code that fixes bugs, adds new features or applies security updates far less frequently than we would like.
This is frustrating to everyone involved, and not surprisingly, many people have tried to speed up the software deployment process with concepts such as dev-prod-parity (keep development, staging, and production as similar as possible) and continuous integration, and tools such as Vagrant and Docker.
For the project I am currently working on I have started to add better test coverage and the continuous integration build is currently passing:

It is a Ruby project and I can use capistrano to deploy a new version to the production server in about a minute.
The data center
The above is unfortunately a very developer-centric view. Deployment is more than pushing updated code to a server. We also need to worry about installing/updating all required software on the server and making configuration changes where needed. And we need to worry about how the server is configured in our data center in terms of access to the internet, security settings, etc. Although there is often an overlap in the tools we can use, deployment really has three aspects:
- code deployment
- server configuration/bootstrapping
- infrastructure configuration
Since starting at DataCite last week, I have spent a good amount of my time working on #2 and #3. The basic assumption is that infrastructure is code.
Server configurations don't change that often, so it is more important to make sure the server is configured exactly as expected rather than saving a few minutes of time. A good approach is therefore to automate the building of a virtual machine or container of the server. DataCite is using Amazon AWS for hosting, and I am using Packer and Chef to automatically build an Amazon Machine Image (AMI) for the server I am working on currently. If you want to follow along (and have an AWS account and the open source Packer and Chef installed), git clone the repo and issue this command:
packer build template.jsonTo add the AMI we just build to the data center; I use terraform. The beginning of the server configuration (in a private repo because security groups, etc. are also included) is:
provider "aws" {
access_key = "${var.access_key}"
secret_key = "${var.secret_key}"
region = "${var.region}"
}
resource "atlas_artifact" "labs-search" {
name = "datacite/doi-metadata-search"
type = "amazon.ami"
build = "latest"
}A terraform apply will build the infrastructure described by terraform. As the last step we need to run capistrano to deploy the latest code (not included in the AMI because the app is currently under heavy development).
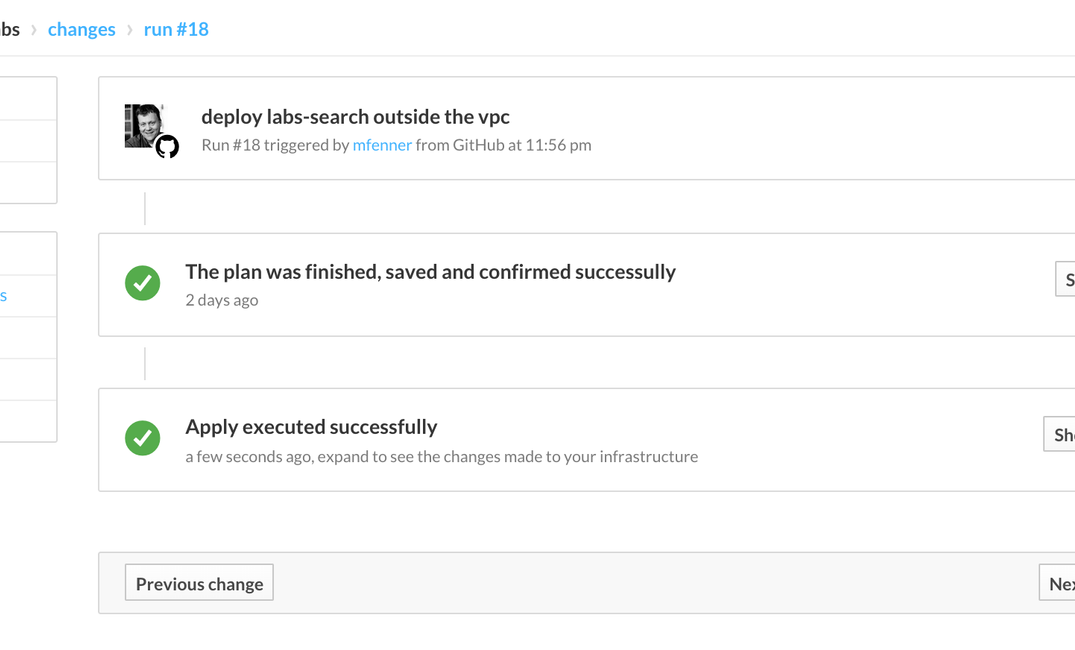
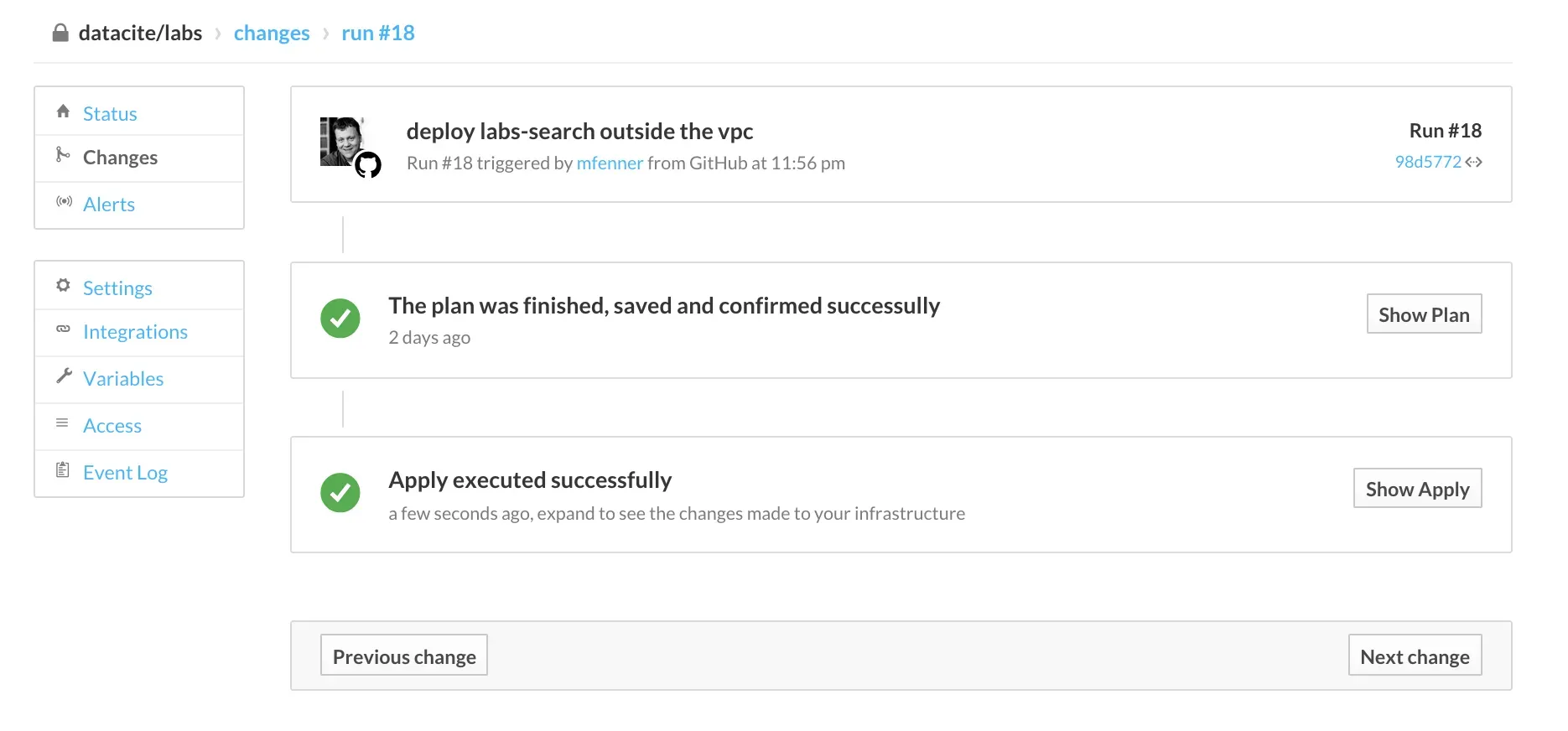
To link the above workflows together we use Atlas, a commercial tool, but free for the number of servers that we need to manage at DataCite. One of the nice features of Atlas is that we can trigger terraform runs by changing the terraform configuration files stored in a Github repository, so really infrastructure as code:
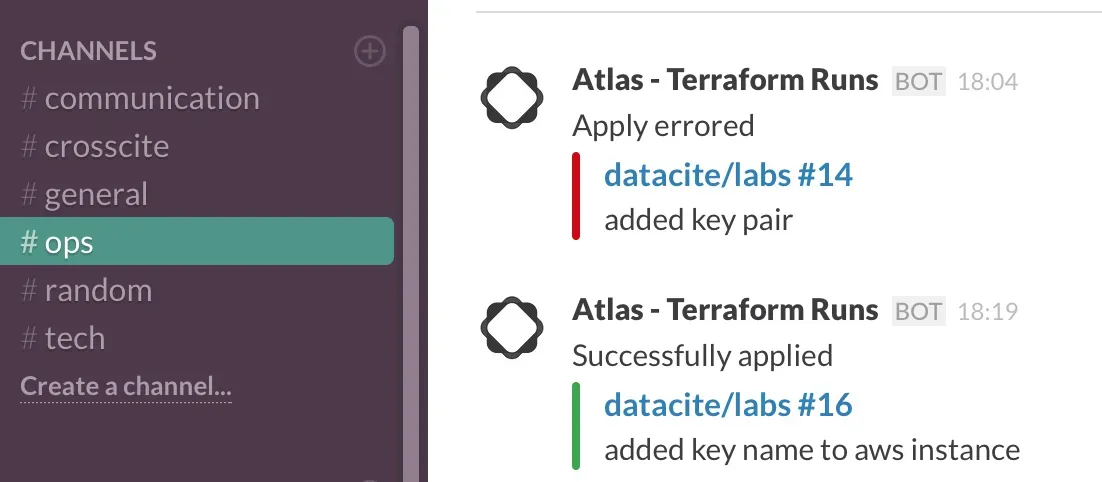
Finally, we want to notify the team when applying these changes to the DataCite infrastructure, and we use email and Slack for this:
I am working on integrating Docker into this workflow, as Docker containers are much more flexible than Amazon Machine Images.
This post is a pretty long-winded way of saying we need to fix a typo at data.datacite.org, but this is of course only one of several issues on our list of bugs to fix.
This blog post was originally published on the DataCite Blog.
