
This blog started registering DOIs for its content with Crossref last week, and all 450+ blog posts so far were registered by Monday morning. This enables the easy import into reference managers (here using Zotero):
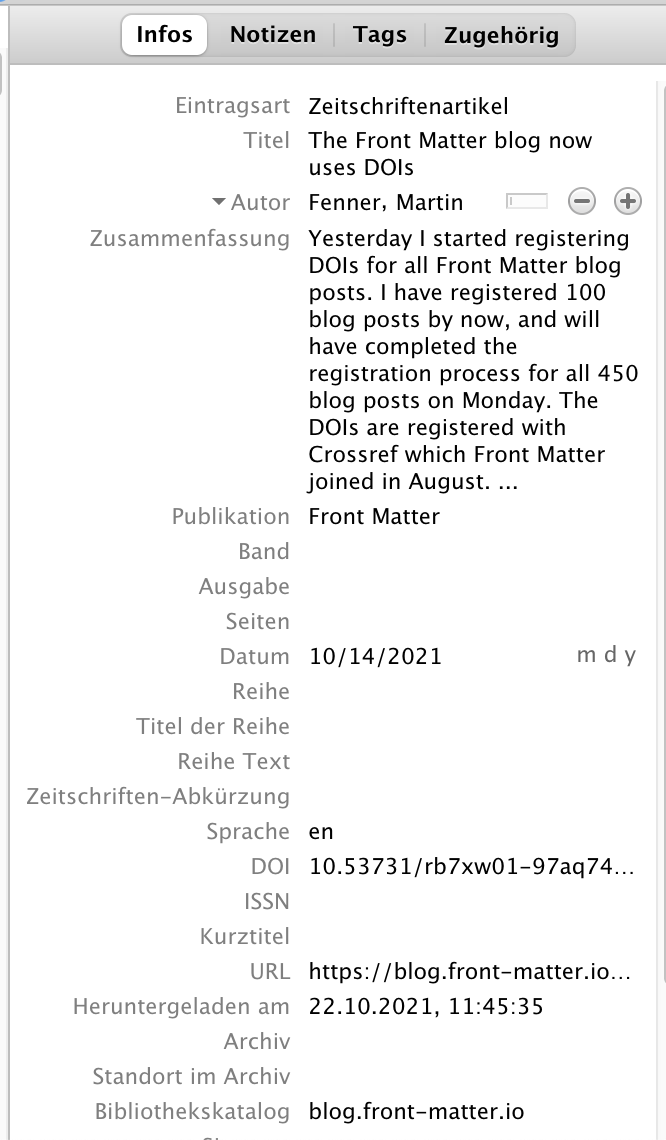
Using Zotero or any other reference manager this blog post can now be easily cited:
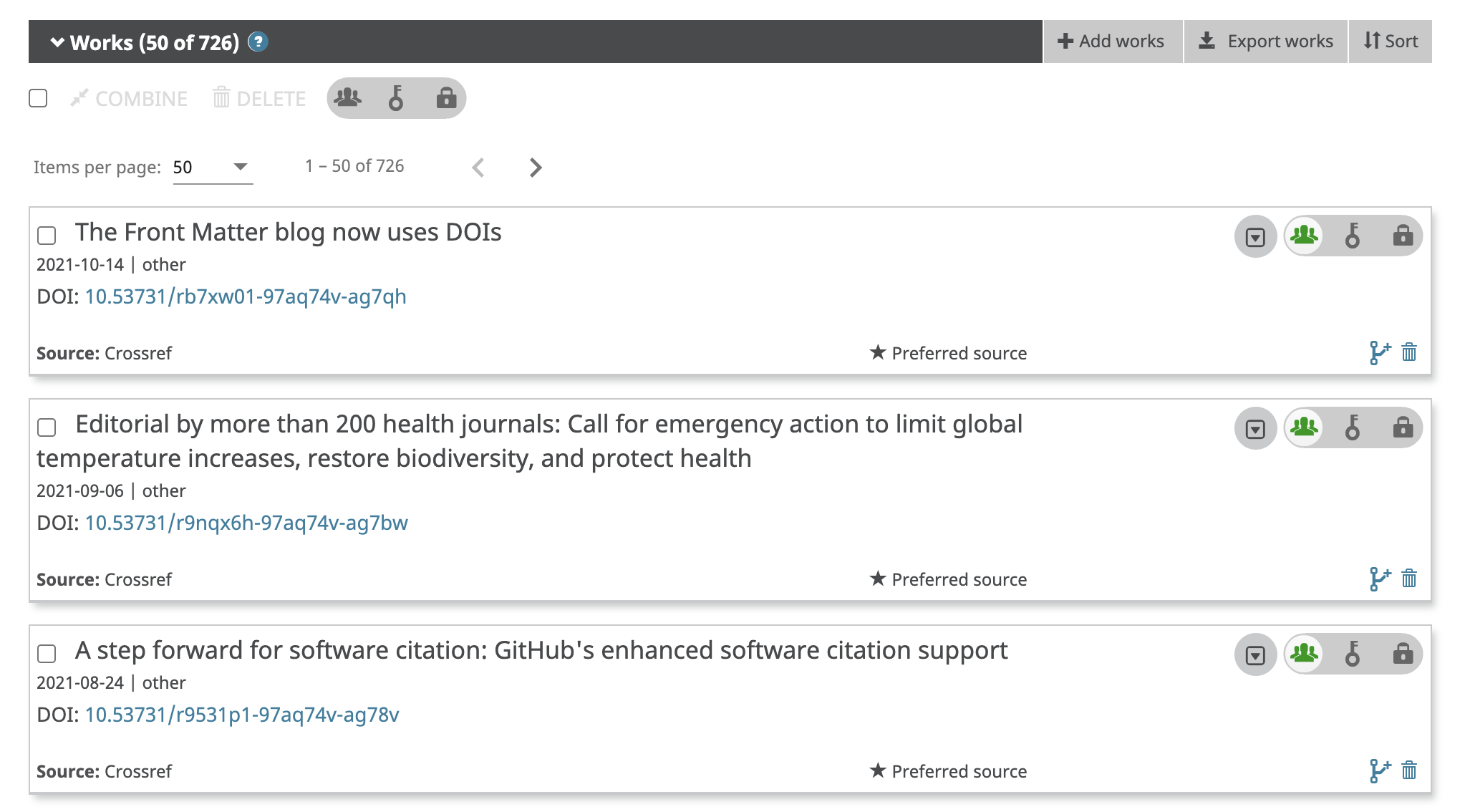
1. Fenner M. The Front Matter blog now uses DOIs. Front Matter. Published online October 14, 2021. doi:10.53731/rb7xw01-97aq74v-ag7qh
And as the author ORCID ID(s) are included in the Crossref metadata, Crossref Auto-Update was automatically updating my ORCID record:
It is too early to say whether the inclusion in the Crossref search index has increased the discoverability of the Front Matter blog. It is also too early to find any Front Matter blog posts referenced in Crossref Event Data, e.g. tweets or Wikipedia pages. We will have some answers in a few months. But it is clear that DOIs can facilitate the discussion around scholarly content, which is the whole point of registering DOIs for blog posts.
DOI registration for blog posts is not very common. I started DOI registration for the DataCite blog in January 2017, and have now simplified the registration workflow for the Front Matter blog:
- Expose blog post schema.org metadata in JSON-LD format on blog post landing page
- Convert metadata to DataCite XML or Crossref XML
- Submit XML to DOI registration agency
The initial work involves generating metadata in schema.org format:
{
"@context": "https://schema.org",
"@type": "BlogPosting",
"@id": "https://doi.org/10.53731/rb7xw01-97aq74v-ag7qh",
"url": "https://blog.front-matter.io/posts/the-front-matter-blog-now-uses-dois",
"name": "The Front Matter blog now uses DOIs",
"headline": "The Front Matter blog now uses DOIs",
"description": [
"Yesterday I started registering DOIs for all Front Matter blog posts. I have registered 100 blog posts by now, and will have completed the registration process for all 450 blog posts on Monday. The DOIs are registered with Crossref which Front Matter joined in August. ..."
],
"author": {
"@type": "Person",
"@id": "https://orcid.org/0000-0003-1419-2405",
"name": "Martin Fenner",
"image": "https://www.gravatar.com/avatar/8adea77ad740876f5cb832f92d49f08d?s=250&d=mm&r=x"
},
"isPartOf": {
"@type": "Blog",
"name": "Front Matter",
"issn": "2749-9952"
},
"publisher": {
"@type": "Organization",
"name": "Front Matter"
},
"keywords": "news",
"inLanguage": "en",
"license": "https://creativecommons.org/licenses/by/4.0/legalcode",
"dateCreated": "2021-10-14T08:49:04Z",
"dateModified": "2021-10-14T14:14:52Z",
"datePublished": "2021-10-14T13:43:48Z"
}It makes sense to not only think about metadata required for DOI registration, but also include recommended metadata such as license, language, description and ORCID ID.
For steps 2. and 3. I have written a GitHub Action that fully automates the DOI registration, triggered by a webhook when the blog post is published. As part of this work I had to enable Crossref XML generation in the bolognese Ruby gem, this pull request is currently awaiting review. I hope that I can publish the GitHub Action in a few weeks.
