
The InvenioRDM project partners met in Hamburg two weeks ago, and we discussed a wide range of topics over five days. InvenioRDM is the open source repository platform that also powers the Rogue Scholar science blog archive, and one priority for me is to keep the repository platform's maintenance simple while adding the features I need.
The workshop motivated me to work on author affiliations, inspired by a session on using programming languages other than Python or JavaScript for tasks that require a lot of data processing and network traffic.
One core functionality of InvenioRDM and Rogue Scholar is information about author affiliations, using the Research Organization Registry (ROR) persistent identifier. About 100K organizations relevant for the scholarly community are included in ROR with a persistent identifier and relevant metadata such as names in multiple languages, organization type, geolocation, and other organizational identifiers (disclaimer: I was heavily involved in launching the ROR registry in early 2019).
To make this functionality work, InvenioRDM stores information about affiliations from a YAML file into the InvenioRDM database, allowing users to pick an affiliation via the InvenioRDM user interface.
This YAML file contains only a small subset of the metadata made available via ROR, basically only the ROR ID and organization names in one or more languages.
ROR releases an updated data dump once a month, a 59 MB compressed file containing metadata for all records in JSON and CSV formats. To extract all records from the 257 MB uncompressed JSON file and store the metadata needed for InvenioRDM in a YAML file is not difficult, but it requires automation and is a good task for the Go programming language. I updated the commonmeta Go library to do this with version v0.17.5 released today. To convert a ROR data dump in JSON format into a YAML file InvenioRDM can understand, run this command:
commonmeta transform v1.63-2025-04-03-ror-data_schema_v2.json --from ror --to inveniordm --file affiliations_ror.yamlThis step takes about five seconds. You can also generate a compressed version by adding the --compress flag. This brings the size of the YAML file containing all 115K ROR records down from 21 MB to 4.1 MB.
But you can go one step further. commonmeta is a single Go binary without dependencies. In version v0.17 I added the compressed ROR records in InvenioRDM YAML format to the commonmeta binary, increasing the file size from 4 MB to 8 MB. You can now output the same YAML file with this command (i.e., without the ROR JSON input file):
commonmeta transform --to inveniordm --file affiliations_ror.yamlThis command runs without any network operations. As Golang programs are distributed as a single binary, embedding files is a convenient way to distribute metadata and/or content together with code.
The process of downloading the latest ROR data dump could also be optimized. One challenge is the direct download of files, as the DOI of the data dump resolves to the record landing page on Zenodo, and more work is needed to get the download links from the API in an automated fashion.
InvenioRDM Starter
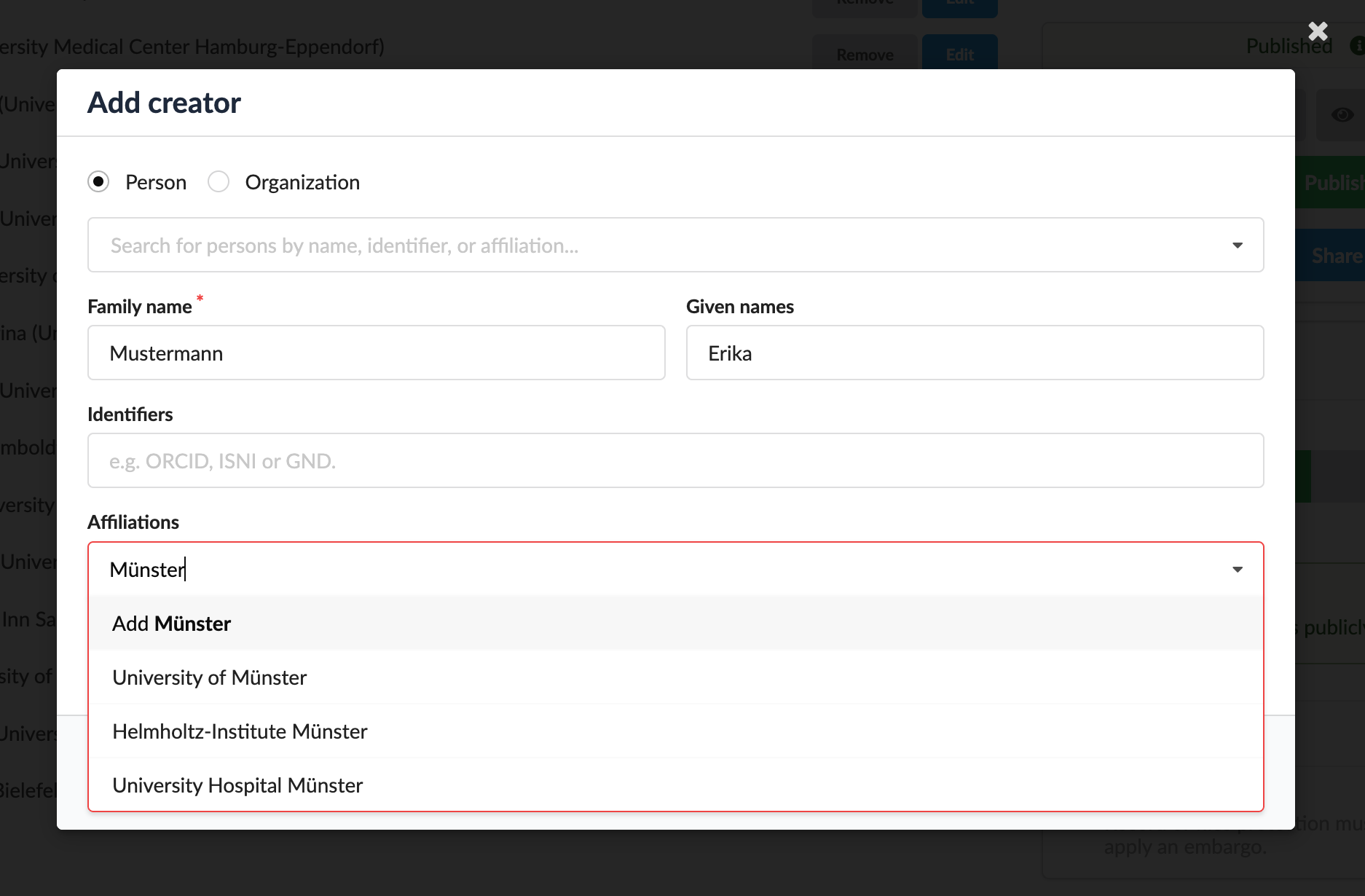
For a smooth start with InvenioRDM, I am maintaining the InvenioRDM Starter project that includes a prebuilt InvenioRDM Docker image and can be started with the included Docker Compose file. The commonmeta Go library can provide data to load into your InvenioRDM Starter instance by querying DataCite, Crossref, or other InvenioRDM instances (not working yet with Zenodo because the API is highly customized to be backward-compatible). One obvious use case is to load Crossref or DataCite DOI metadata from authors from a particular institution using the ROR identifier, for example 1000 Crossref records from the University of Münster (ROR ID https://ror.org/00pd74e08):
commonmeta push -f crossref -t inveniordm --ror 00pd74e08 -n 1000 --host localhost --token xxxTo do the same query with DataCite, replace the -f (from) flag:
commonmeta push -f datacite -t inveniordm --ror 00pd74e08 -n 1000 --host localhost --token xxx
You first need to create an account and set up a token in your InvenioRDM Starter instance running at https://localhost. And you need to do one additional step: load all ROR affiliations that you need. You have two options: a) load the file with all ROR affiliations created above, or b) only load the ROR affiliations you need for your test data. The former is challenging as the import of more than 100K affiliations via API can be tricky. To do the latter, you can generate an JSON file with your metadata first and generate an affiliations_ror.yaml file with the --vocabulary flag:
commonmeta list -f crossref -t inveniordm --ror 00pd74e08 -n 1000 --vocabularyThere is unfortunately still a bit work needed to get all this working. But the end result is something like this in your InvenioRDM Starter instance:
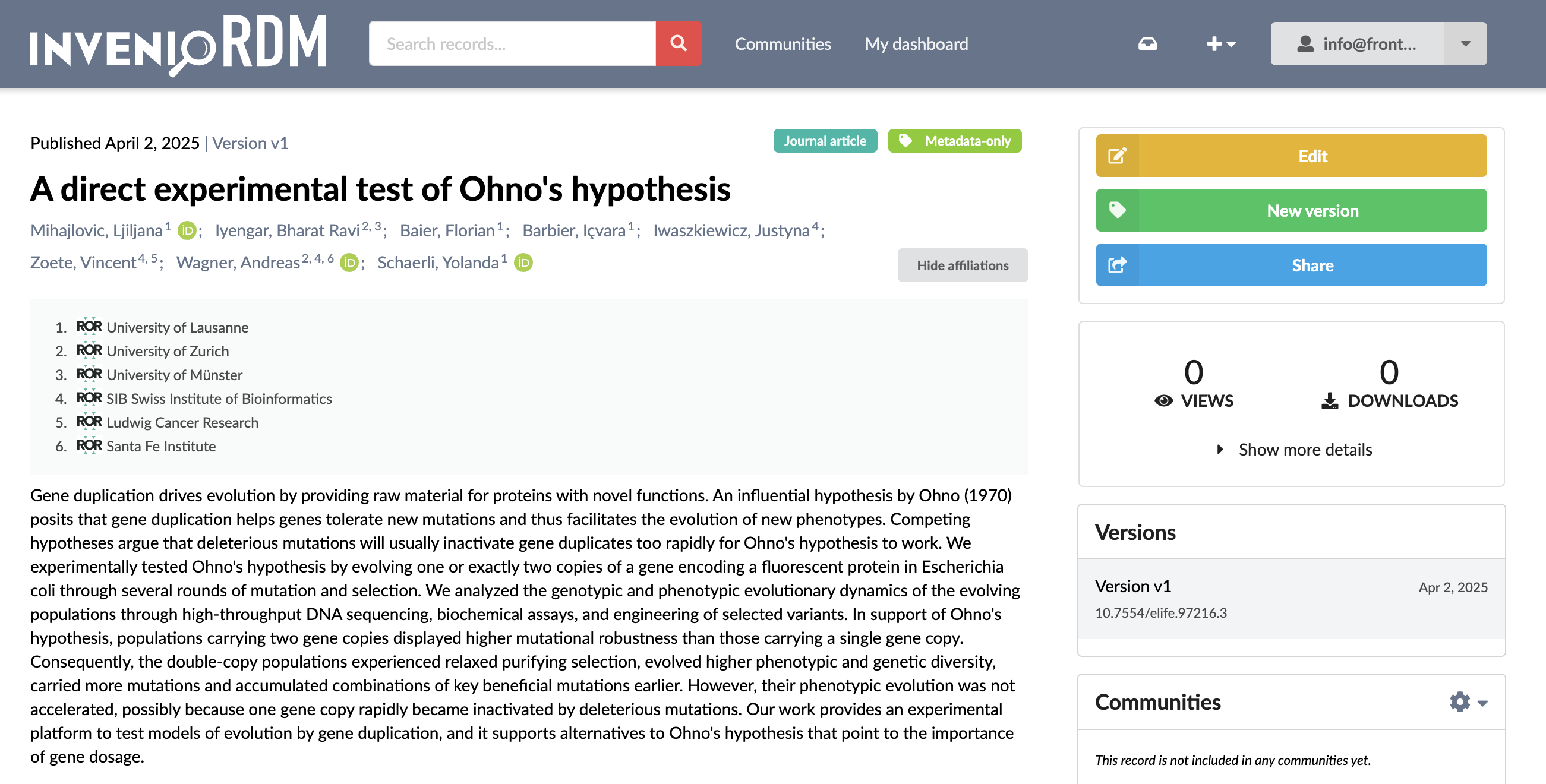
This also works with the hundreds of authors and their affiliations common to high-energy physics:
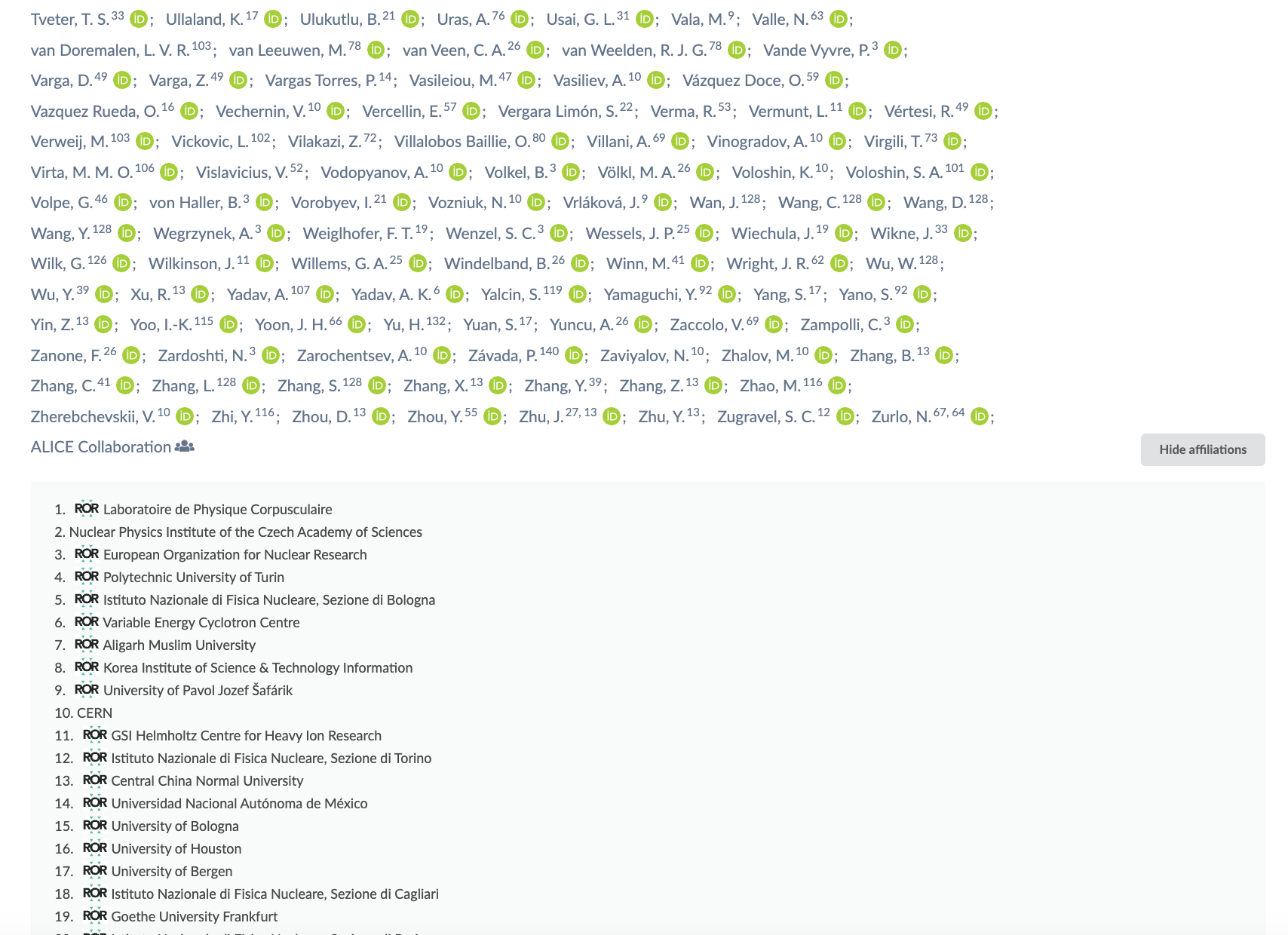
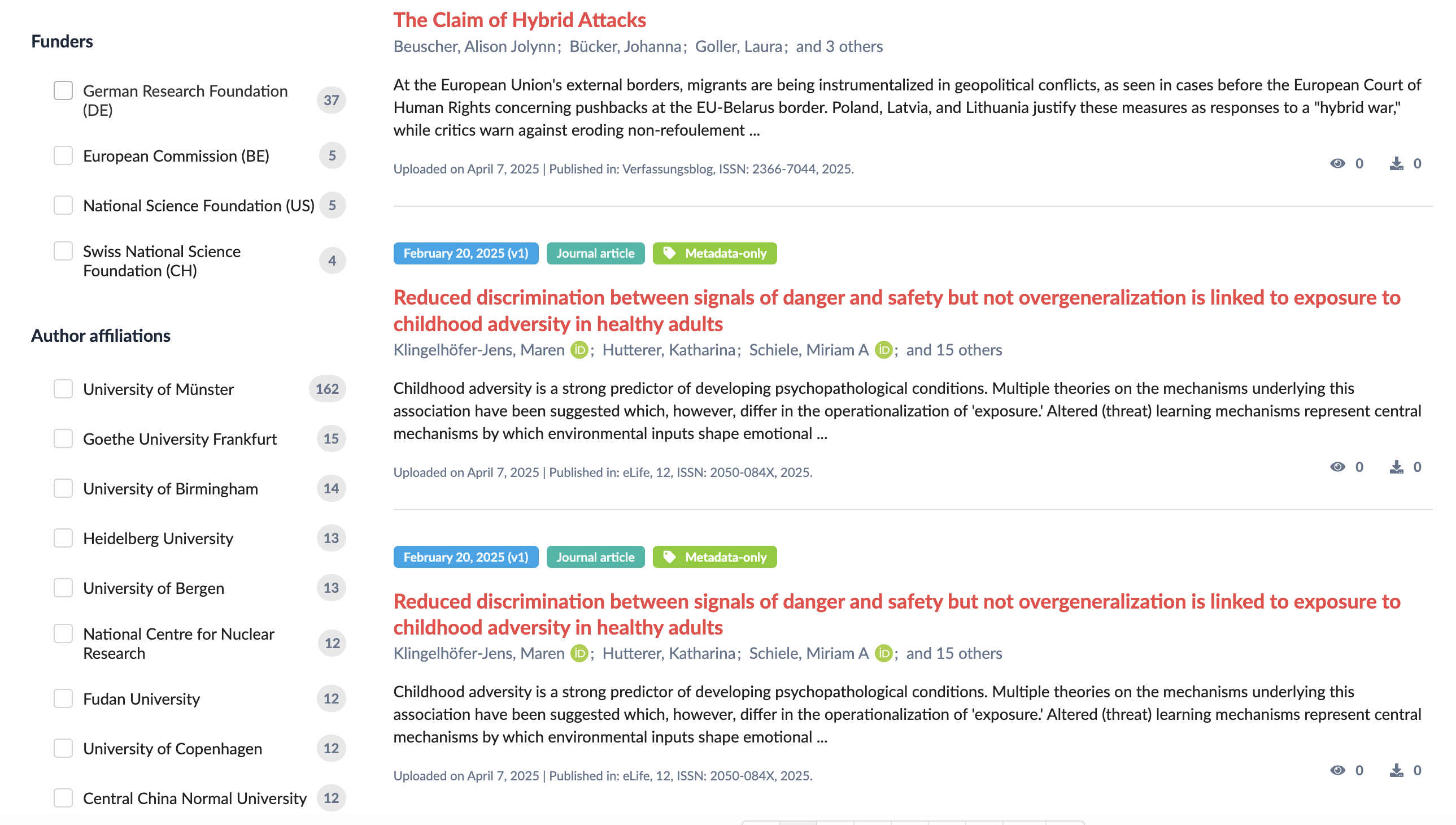
And ROR is also used for the search facets, allowing you to filter records by affiliation (e.g. co-autors from outside the University of Münster):
The improved tooling for working with ROR metadata enables a lot of interesting functionality for institutions running an instance of InvenioRDM. A lot more work is needed to improve the documentation and developer experience, but the InvenioRDM Starter example already nicely demonstrates how to quickly get external metadata into InvenioRDM without intermediaries such as research information systems (CRIS).
References
- Gould, M. (2019). Hear us ROR! Announcing our first prototype and next steps. ROR blog. https://doi.org/10.71938/0EH7-XG96
- Research Organization Registry. (2025). ROR Data (Version v1.63) [Dataset]. Zenodo. https://doi.org/10.5281/ZENODO.6347574
- Martin Fenner. (2025). front-matter/commonmeta: V0.17.5 (Version v0.17.5) [Computer software]. Zenodo. https://doi.org/10.5281/ZENODO.15169107
