DataCite is a DOI registration agency that enables the registration of scholarly content with a persistent identifier (DOI) and metadata. This content can then be searched for, reused, and connected to other scholarly resources. But how does the underlying infrastructure enable this? In this blog post, we will describe what we have built to make this work. This is a fairly technical post, as I tried to go a little deeper into the details.
Cloud hosting and DevOps
DataCite is a small nonprofit organization (currently 12 team members, including three in the development team), and the team is fully remote. All our infrastructure is running in the Cloud (most of it using Amazon Web Services (AWS), with the servers that store data located in Ireland). We have automated the operation of our services as much as possible, following DevOps best practices. Because of the small team size, we have no separation of software development and system administration teams, and DevOps allows us to highly integrate these roles. Two important automation tools we use are GitHub Actions for Continues Integration/Continues Deployment (CI/CD) and Terraform for managing “Infrastructure as Code”. While we are using Terraform since 2016, we have only recently migrated our CI/CD workflows from Travis CI (finishing the migration in the next few months), mainly because GitHub Actions come with many ready-to-use actions for some of the more complex parts of our deployment pipeline. All DataCite software is available with an open license in a public GitHub repository, and that also includes our GitHub actions and Terraform configurations. You can for example find the code for our REST API here, and the corresponding GitHub actions here.
DataCite backend services
The DataCite backend uses services that store data (files or databases), and we use managed AWS services for those, e.g. RDS to manage our MySQL relational databases. Our APIs are all running as stateless Docker containers, and we use the Amazon Elastic Container Service (ECS), in combination with Amazon Application Load Balancers to manage those. The adoption of Docker containers was the biggest change in our infrastructure 2016-2019, and we have developed a lot of expertise in this area. Going forward we will switch to Kubernetes (AWS Kubernetes Service) at some point, as it has become the de-facto standard for container management in the cloud and provides additional functionalities in a widely-used open source platform. In 2015 all backend services were written in Java, over the last six years – as we upgraded our services one after another – this has changed to backend services written in Ruby and Python. This might again change going forward, we have for example started to use an open source software for collecting usage stats that is written in Elixir. While we have to be careful as a small development team to not spread our expertise too wide, we need to be open to new technologies, and a grant-funded project that can be based on existing open source software
DataCite frontend services
The DataCite frontend services have over time been clearly separated from backend services, with only one service still running as a full-stack service (mainly because of the special needs for authentication). DataCite Fabrica is our main service for account management and DOI registration and was originally launched in September 2017. Fabrica uses the Ember.js Javascript framework. Ember.js addresses the needs we have for this service but has not seen the same level of adoption as some other Javascript frameworks, namely React or Vue. When we launched DataCite Commons – our replacement for the DataCite Search discovery service – in October 2020, we decided to use the Next.js framework (based on React), together with GraphQL as the query language for our APIs. Next.js supports server-side rendering, which enabled us to provide embedded metadata (in particular in schema.org format) that are picked up by Google (e.g. for Google Dataset Search) and other indexers. The initial experience has been positive and we are going to not only build out the functionality – and performance – of DataCite Commons, but over time also transition our legacy frontend services to the same platform – currently we are using six different technologies for those, as they were built over time in the last ten years. We can then also explore more the use of serverless as a technology to support our frontend services, as we are doing with DataCite Commons, running on the Vercel platform.
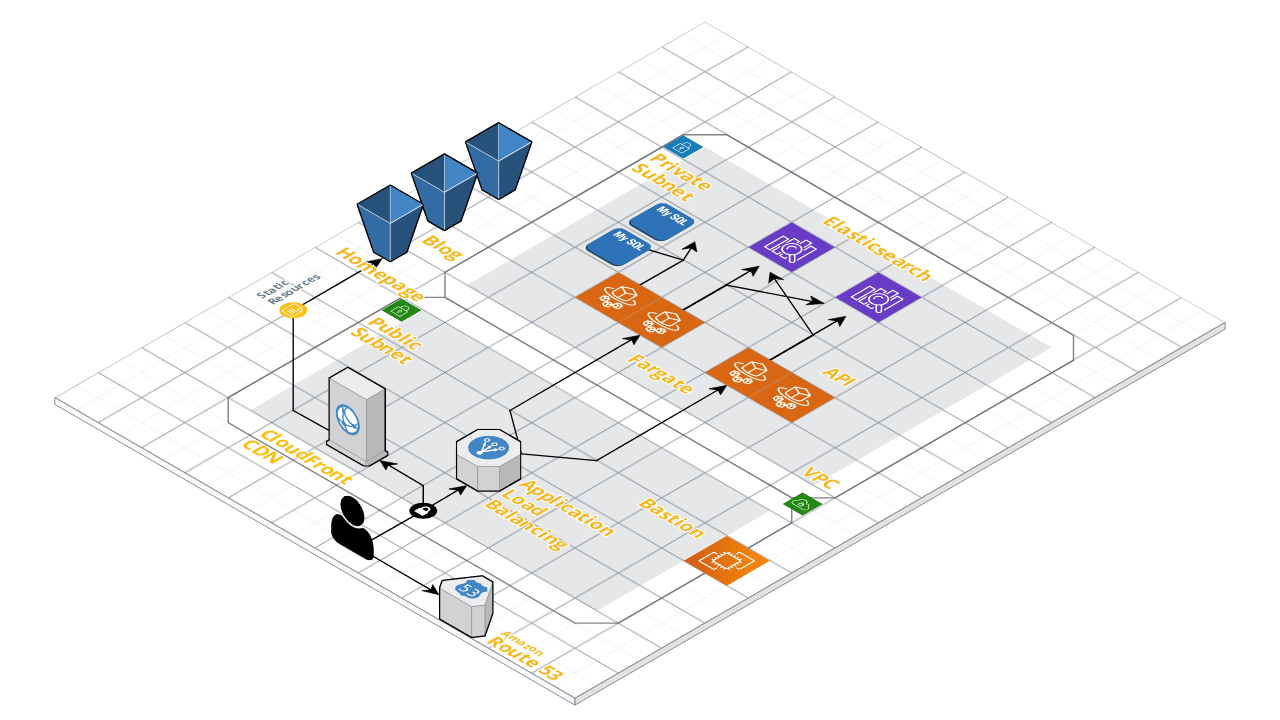
The following picture puts everything I talked about together into a single view (obviously omitting a lot of detail):
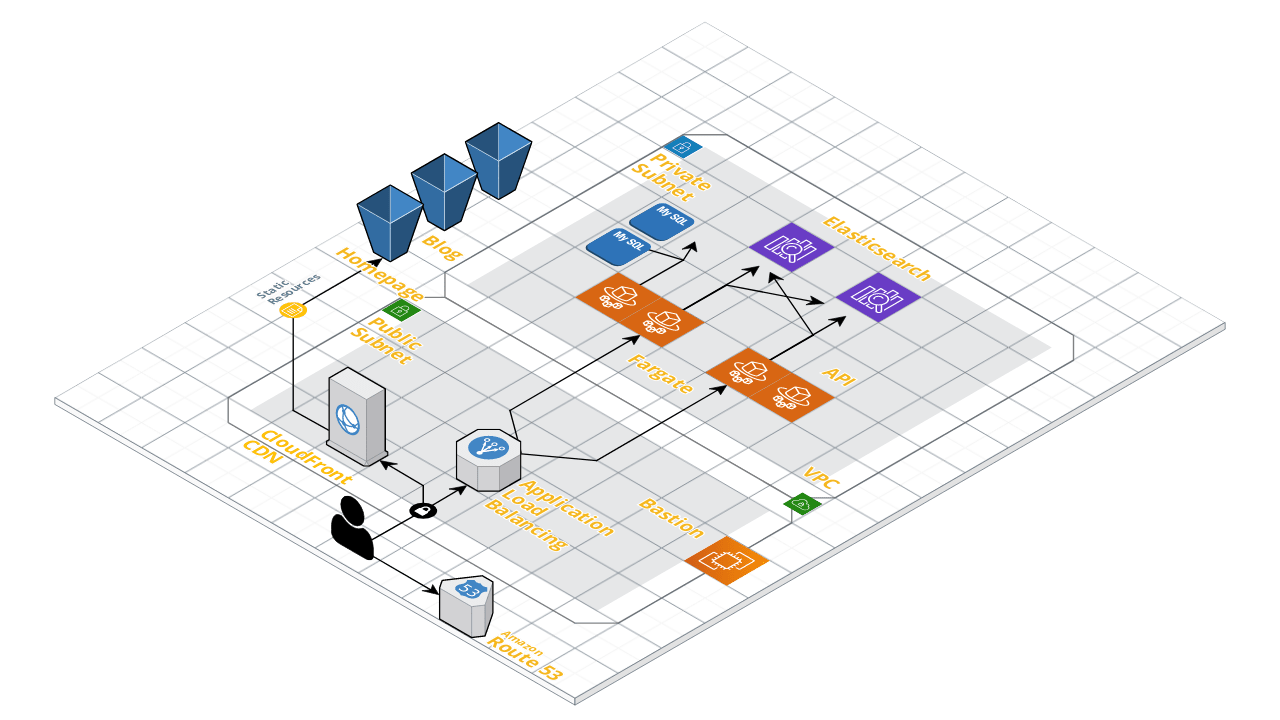
Please feel free to reach out to me if you have any questions about the DataCite technology stack. If you are now interested in working for the DataCite development team, you can find more information about an open position here.
Acknowledgments
This blog post was originally published on the DataCite Blog.
