
On July 12, 2016, DataCite invited Andreas Rauber to present the recommendations for dynamic data citation of the RDA Data Citation Working Group in a webinar.
Andreas is one of the co-chairs of the RDA working group, and he gave a throughout overview of the recommendations, and the thinking that went into them. The final recommendations are available since last fall, and the current focus of the working group is to help with implementations.
The recommendations have to be implemented in the data center, but DataCite is happy to help coordinate the work, and to provide feedback to Andreas and the rest of the working group where needed. Of particular importance from a DataCite perspective is recommendation 8:
Query PID: Assign a new PID to the query if either the query is new or if the result set returned from an earlier identical query is different due to changes in the data. Otherwise, return the existing PID.
Assigning a persistent identifier (not only) when a dataset is originally generated, but also when a dataset is about to be cited, is central not only to the working group recommendations for dynamic data citation, but also crucial for other data citation use cases. Data exist at different levels, from raw data possibly generated by a machine, to highly processed data used in a publication. The figure below – presented by Robin Dasler from CERN at the THOR Workshop on July 7 in Amsterdam - demonstrates this for high-energy physics (HEP):
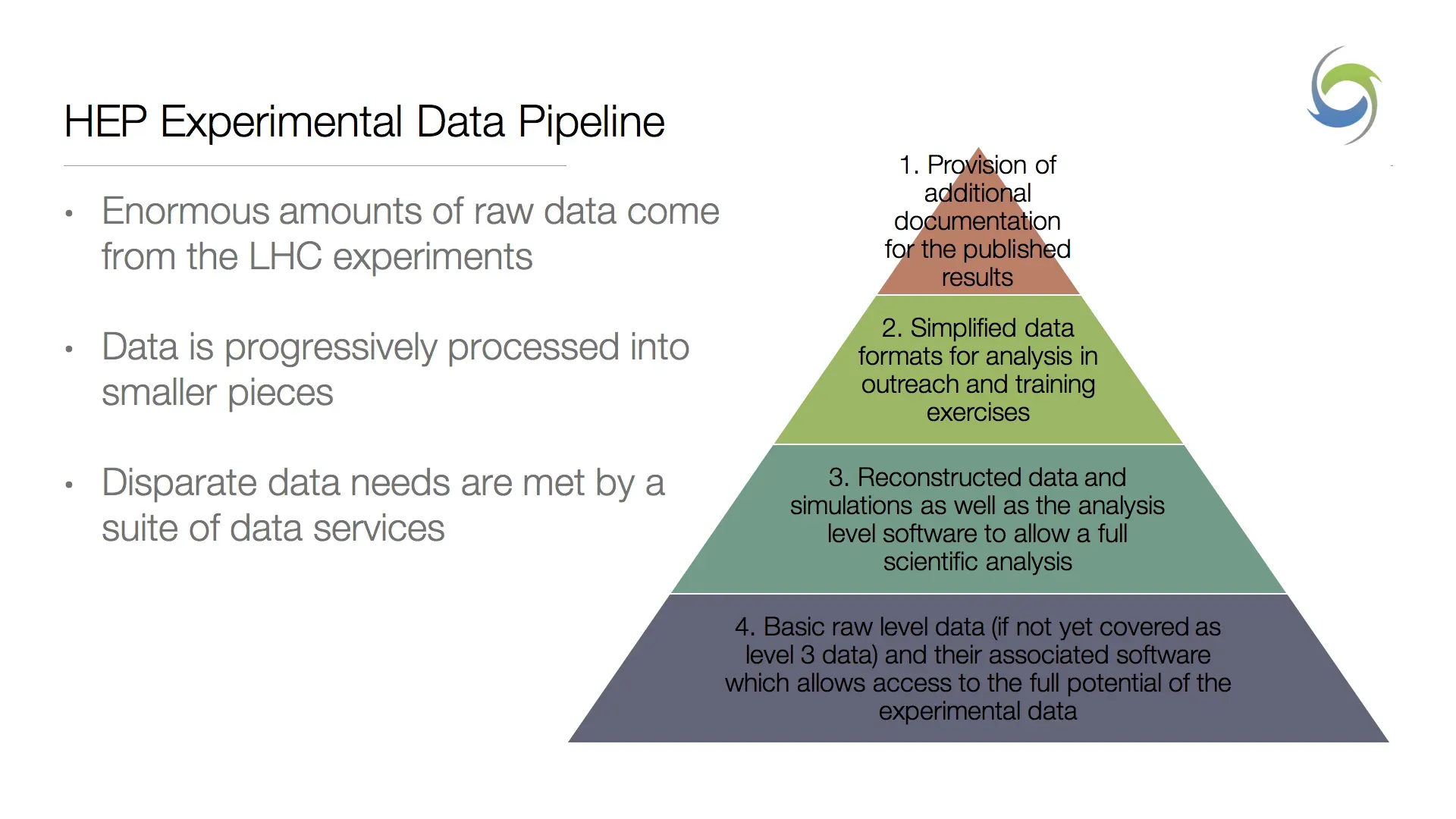
DataCite DOIs are intended as citation identifiers. They are persistent identifiers and provide standardized metadata, including links to associated publications, contributors and funders. They thus focus on the data in the top section of the pyramid. While we can also use DataCite DOIs for the other levels of the pyramid, sometimes other identifiers are more appropriate for raw, non-persistent data generated by machines. Dynamic data citation can be seen as a variant of the process that this pyramid describes.
If you could not attend last week or you want to review the session, the recording of the webinar is available:
The THOR project will work with interested data centers on dynamic data citation in the coming 12 months, hopefully leading to important feedback and a few more implementations of the RDA working group recommendations. Please contact us if you work for a data center and are interested in participating.
Acknowledgments
This blog post was originally published on the DataCite Blog.
