Last week Google Scholar announced a new feature on the Google Scholar Blog: Google Scholar Citations. The stated purpose of this tool is to allow researchers to calculate their citation metrics, e.g. their Hirsch index (H-index).
This is an interesting new service, that not only helps with calculating citation metrics, but also shows you who is citing your papers – a great discovery tool. Signup to Google Scholar Citations is currently limited, but I was able to create a profile here.
The problem? We have this service already. Scopus, Researcher ID and others have provided this information for some time, and Google Scholar Citations looks very much like a response to the recently launched Microsoft Academic Search:

Will we soon see a similar offering from Mendeley or ResearchGate? There is of course nothing wrong with competition, and there is no reason why we can’t have more than one place that provides researcher profiles. But as I have argued before,
Systems that measure and evaluate scientific contributions can and should be separate from the databases that hold the scholarly record.
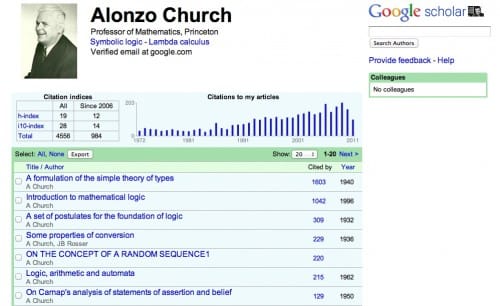
It is not only a waste of resources (both Google Scholar’s and the individual researchers’ who maintain their profiles) to many many different bibliographic databases, but it also makes it impossible to compare citation metrics. In the examples above Alonzo Church has a H-index of 19 at Google Scholar, but only 11 at Microsoft Academic Search (and probably again a different one somewhere else). This means that we can only use an H-index when we mention where (and when) it was calculated.
The better solution is a common open bibliography, and the difference between the various service would be how they calculate the citation metric or present the bibliographic data – you can see the different approaches taken by Google Scholar and Microsoft Academic Search in the screenshots above. This is a difficult task, but not impossible to do. The first step would be to realize that having a common open bibliography would create tremendous value for everybody as we can start building tools on top this bibliography without requiring to collect all the bibliographic data ourselves. We see something like this happening in smaller domains, and the tools using the PubMed database are a good example.
From a researcher perspective it makes little sense to have many different places where you can maintain your publications. It makes much more sense to do this once and then see the information reused in different services. This is the approach the Open Researcher & Contributor ID initiative is taking:
All profile data contributed to ORCID by researchers or claimed by them will be available in standard formats for free download (subject to the researchers’ own privacy settings) that is updated once a year and released under the CC0 waiver.
Disclaimer: I sit on the Board of Directors of the Open Researcher & Contributor ID (ORCID) initiative which aims to help solve this and related problems.
